A mule project contains MySQL database dependency . The project is exported from Anypoint Studio so that it can be deployed to Cloudhub. What export options needs to be selected to create the smallest deployable archive that will successfully deploy to Cloudhub?
A. Select both the options 1) Attach project sources 2) Include project module and dependencies
B. No need to select any of the below options 1) Attach project sources 2) Include project module and dependencies
C. Select only below option 2) Include project module and dependencies
D. Select only below option 1) Attach project sources
Explanation:
You can choose Attach Project Sources to include metadata that Studio requires to reimport the deployable file as an open Mule project into your workspace. You must keep the Attach Project Sources option selected to be able to import the packaged JAR file back into a Studio workspace. But requirement here is to create smallest deployable archive that will successfully deploy to Cloudhub. Hence we can ignore this option.
We need to select Include project module and dependencies As actual modules and external dependencies required to run the Mule application in a Mule runtime engine Hence correct answer is Select only below option 2) Include project module and dependencies
Refer to the exhibits.

A web client sends sale data in a POST request to the Mule application. The Transform Message component then enrich the payload by prepending a vendor name to the sale data.
What is written to the sales.csv file when the flow executes?
A. The enriched payload in JSON format
B. The enriched payload in XML format
C. The enriched payload in CSV format
D. An error message
How can you call a subflow from Dataweave?
A. Not possible in Mule 4
B. Import function
C. Lookup function
D. Include function
Explanation:
This is a trick question.
You can call only flows from DataWeave using lookup function. Note that lookup function does not support calling subflows.
A subflow needs a parent context to inherit behaviors from such as exception handling, which a flow does not need Hence correct answer is Not possible in Mule 4
What is the main purpose of flow designer in Design Center?
A. To design and develop fully functional Mule applications in a hosted development environment
B. To design API RAML files in a graphical way
C. To design and mock Mule application templates that must be implemented using Anypoint Studio
D. To define API lifecycle management in a graphical way
Explanation: Its primary function is to design and develop fully functional Mule applications in a hosted development environment.
Refer to the exhibit.
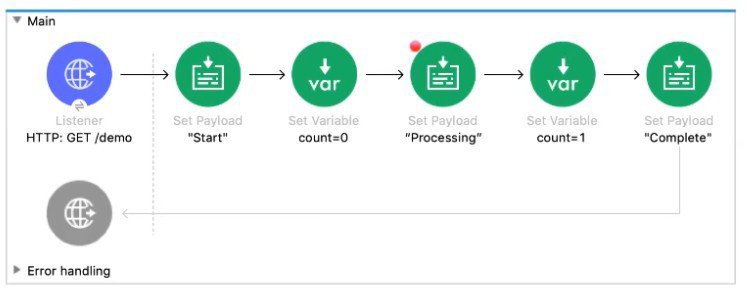
The Mule application Is debugged in Any point Studio and stops at the breakpoint What is the value of the payload displayed In the debugger at this breakpoint?
A. 0
B. "Processing"
C. "Start"
D. Complete"
Refer to the exhibits.
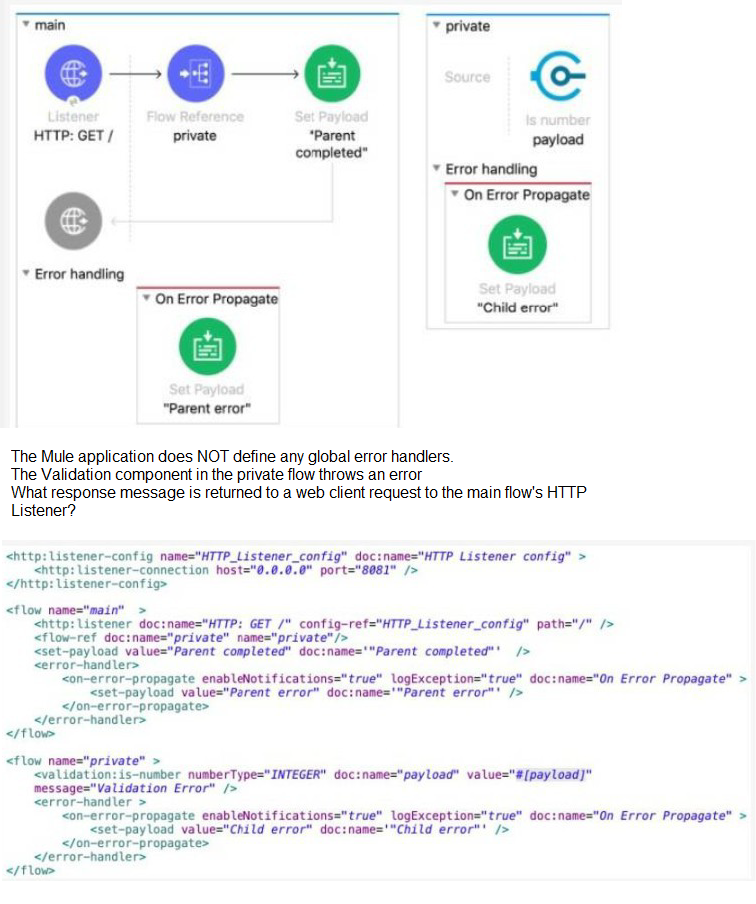
A. ''Child error"
B. "Parent error"
C. "Validation Error"
D. "Parent completed"
Following Mulesoft's recommended API-led connectivity approach , an organization has created an application network. The organization now needs to create API's to transform , orchestrate and aggregate the data provided by the other API's in the application network. This API should be flexible enought ot handle the data from additional API's in future.
According to Mulesoft's recommended API-led connectivity approach , what is the best layer for this new API?
A. Process layer
B. System layer
C. Experience layer
D. Data layer
Explanation:
Correct answer is process layer as all the orchestration and transformation logic should be
in process layer as per Mulesoft's recommended approach for API led connectivity.
API-led connectivity is a methodical way to connect data to applications through reusable and purposeful APIs. These APIs are developed to play a specific role – unlocking data from systems, composing data into processes, or delivering an experience.
What are the APIs that enable API-led connectivity?
API-led connectivity provides an approach for connecting and exposing assets. With this approach, rather than connecting things point-to-point, every asset becomes a managed API – a modern API, which makes it discoverable through self-service without losing control.
The APIs used in an API-led approach to connectivity fall into three categories:
System APIs – these usually access the core systems of record and provide a means of insulating the user from the complexity or any changes to the underlying systems. Once built, many users, can access data without any need to learn the underlying systems and can reuse these APIs in multiple projects.
Process APIs – These APIs interact with and shape data within a single system or across systems (breaking down data silos) and are created here without a dependence on the source systems from which that data originates, as well as the target channels through which that data is delivered.
Experience APIs – Experience APIs are the means by which data can be reconfigured so that it is most easily consumed by its intended audience, all from a common data source, rather than setting up separate point-to-point integrations for each channel. An Experience API is usually created with API-first design principles where the API is designed for the specific user experience in mind.
Refer to the exhibits.
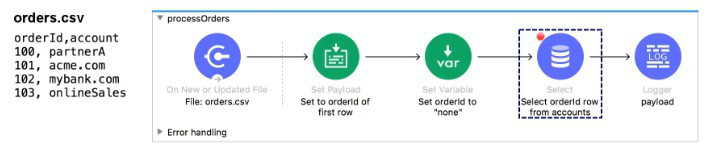
The orders.csv file is read, then processed to look up the orders in a database. The Mule application is debugged in Any point Studio and stops at the breakpoint.
What is the payload shown in the debugger at this breakpoint?
A. "none"
B. The entire CSV file
C. The database response
D. 100
What is the correct syntax to define and call a function in Database?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
Keyword to ad function in Dataweave transformation is fun. Hence option 2 and 4 are invalid. Also parameters needs to be passed exactly in same order as defined in function definition. Hence correct answer is'
fun addKV( object: Object, key: String, value: Any) =
object ++ {(key):(value)}
---
addKV ( {"hello': "world"}, "hola", "mundo" )
MuleSoft Documentation Reference : https://docs.mulesoft.com/mule- runtime/4.3/dataweave-functions
DataWeave Function Definition Syntax
To define a function in DataWeave use the following syntax:
fun myFunction(param1, param2, ...) = The fun keyword starts the definition of a function. myFunction is the name you define for the function.
Function names must be valid identifiers.
(param1, param2, … , paramn) represents the parameters that your function accepts. You can specify from zero to any number of parameters, separated by commas (,) and enclosed in parentheses.
The = sign marks the beginning of the code block to execute when the function is called.
represents the actual code that you define for your function.
An API specification is designed using RAML. What is the next step to create a REST Connector from this API specification?
A. Download the API specification and build the interface using APIkit
B. Publish the API specification to Any point Exchange
C. Implement the API specification using flow designer in Design Center
D. Add the specification to a Mule project's src/main/resources/api folder
Explanation: API Exchange creates REST conenctor automtaically once API is published. Hence correct answer is Publish the API specification to Any point Exchange
| Page 8 out of 24 Pages |
| Salesforce-MuleSoft-Developer-I Practice Test Home | Previous |
Copyright © - All Rights Reserved