Total 152 Questions
Last Updated On : 17-Jul-2026
Preparing with Salesforce-MuleSoft-Platform-Architect practice test 2026 is essential to ensure success on the exam. It allows you to familiarize yourself with the Salesforce-MuleSoft-Platform-Architect exam questions format and identify your strengths and weaknesses. By practicing thoroughly, you can maximize your chances of passing the Salesforce certification 2026 exam on your first attempt. Start with free Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 sample questions or use the timed simulator for full exam practice. Surveys from different platforms and user-reported pass rates suggest Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 practice exam users are ~30-40% more likely to pass.

An eCommerce company is adding a new Product Details feature to their website, A customer will launch the product catalog page, a new Product Details link will
appear by product where they can click to retrieve the product detail description. Product detail data is updated with product update releases, once or twice a year, Presently
the database response time has been very slow due to high volume.
What action retrieves the product details with the lowest response time, fault tolerant, and consistent data?
A. Select the product details from a database in a Cache scope and return them within the API response
B. Select the product details from a database and put them in Anypoint MQ; the Anypoint MO subseriber will receive the product details and return them within the API response
C. Use an object store to store and retrieve the product details originally read from a database and return them within the API response
D. Select the product details from a database and return them within the API response
Explanation:
Requirements analysis:
Lowest response time → Avoid hitting slow DB on every request.
Fault tolerant → Should handle failures gracefully.
Consistent data → Data changes only 1–2 times per year (very low update frequency).
High volume → Caching is essential.
Why Object Store fits best
Performance: Object Store (backed by persistent storage like S3 in CloudHub) serves cached data much faster than repeated DB queries.
Fault tolerance: Object Store is distributed and persists across app restarts, unlike in-memory cache.
Data consistency: With updates only 1–2 times per year, we can:
- Load product details from DB into Object Store when data changes.
- Serve all subsequent reads from Object Store.
- Implement a cache refresh mechanism triggered by product updates (manual or event-based).
High volume handling: Offloads DB completely for reads after initial caching.
Why the Other Options Are Incorrect
A. Cache scope (in-memory cache)
❌ Not fault-tolerant — lost on app restart, not shared across workers. In-memory cache is faster but doesn’t guarantee consistency across multiple app instances and is volatile.
B. Anypoint MQ
❌ Message queue adds overhead (publish/subscribe latency). It’s for async messaging, not low-latency synchronous reads. Overkill for this read-heavy, low-update scenario.
D. Direct DB select
❌ Violates “lowest response time” — DB is already slow under high volume. Also less fault-tolerant if DB is overloaded or fails.
Key Concepts & References
Object Store in Mule:
- Persistent key-value store (backed by S3 in CloudHub, or configurable to external storage).
- Shared across workers and survives app redeploys.
- Suitable for infrequently updated reference data caching.
Cache Strategies:
- Write-through/Refresh on update: Since product details update rarely, trigger Object Store refresh when DB updates occur (via admin or event).
- Read-through: First request after refresh loads from DB → Object Store, subsequent reads from cache.
Consistency vs. Performance Trade-off:
With 1–2 updates/year, eventual consistency (cached until explicitly refreshed) is perfectly acceptable.
Summary
For high-volume reads, low-update frequency data where DB performance is poor, using Object Store provides fast response times, fault tolerance (persistent, shared across workers), and sufficient consistency given the update pattern. This is a standard MuleSoft caching pattern for reference data.
Which of the following best fits the definition of API-led connectivity?
A. API-led connectivity is not just an architecture or technology but also a way to organize people and processes for efficient IT delivery in the organization
B. API-led connectivity is a 3-layered architecture covering Experience, Process and System layers
C. API-led connectivity is a technology which enabled us to implement Experience, Process and System layer based APIs
Explanation
API-led connectivity is a core concept in MuleSoft’s Anypoint Platform and is central to the Salesforce MuleSoft Platform Architect I exam. It is an architectural approach that emphasizes the use of reusable, purpose-built APIs to connect applications, data, and devices in a structured and scalable way. However, it goes beyond just technology or architecture—it’s a holistic strategy that involves organizing teams, processes, and tools to enable faster, more efficient IT delivery and digital transformation.
Key Aspects of API-led Connectivity:
Architecture:
It structures APIs into three distinct layers—Experience, Process, and System—to promote modularity and reuse. Each layer serves a specific purpose:
System APIs: Provide access to core systems of record (e.g., ERP, databases) in a secure and standardized way.
Process APIs: Orchestrate data and logic across systems, enabling business processes.
Experience APIs: Deliver tailored data and functionality to specific channels or user experiences (e.g., mobile apps, web).
Organizational Impact:
API-led connectivity aligns IT and business teams by fostering a center for enablement (C4E) model, which encourages collaboration, governance, and reuse of APIs across projects. It shifts organizations from traditional, project-based IT delivery to a productized, reusable API ecosystem.
Process and Culture:
It involves defining clear roles (e.g., API producers, consumers), governance policies, and self-service models to empower teams while maintaining control. This cultural shift is as critical as the technical architecture.
Why Option A is Correct:
Option A captures the essence of API-led connectivity as more than just a technical framework. It highlights the organizational and process-oriented aspects, such as enabling efficient IT delivery through reusable APIs, team collaboration, and governance. This aligns with MuleSoft’s emphasis on API-led connectivity as a methodology that transforms how organizations operate, not just a set of tools or layers.
Why Not the Other Options?
B. API-led connectivity is a 3-layered architecture covering Experience, Process and System layers:
While this is partially correct, it’s incomplete. API-led connectivity is indeed characterized by the three-layer architecture (Experience, Process, System), but this definition focuses only on the technical structure and misses the broader organizational and process-oriented aspects (e.g., C4E, governance, team alignment). Option A is more comprehensive.
C. API-led connectivity is a technology which enabled us to implement Experience, Process and System layer based APIs:
This is incorrect because API-led connectivity is not a specific technology but rather an architectural and organizational approach. While technologies (e.g., MuleSoft’s Anypoint Platform) enable its implementation, API-led connectivity itself is about principles, patterns, and practices, not a single technology.
References
MuleSoft Documentation: What is API-led Connectivity? – Describes API-led connectivity as a methodology that includes the three-layer architecture and emphasizes organizational enablement and reuse.
MuleSoft Whitepaper: API-led Connectivity: The Next Step in the Evolution of SOA – Highlights how it transforms IT delivery by aligning people, processes, and technology.
MuleSoft Training: The MuleSoft Certified Platform Architect – Level 1 (MCPA) course materials emphasize API-led connectivity as a strategy that combines architecture, governance, and organizational change, not just a technical framework.
Refer to the exhibit.
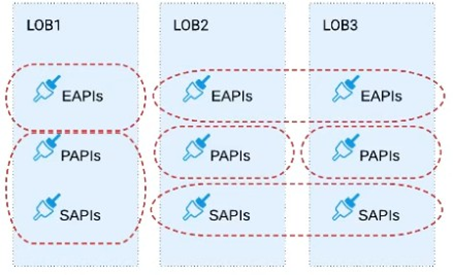
Three business processes need to be implemented, and the implementations need to communicate with several different SaaS applications.
These processes are owned by separate (siloed) LOBs and are mainly independent of each other, but do share a few business entities. Each LOB has one development team and their own budget
In this organizational context, what is the most effective approach to choose the API data models for the APIs that will implement these business processes with minimal redundancy of the data models?
A) Build several Bounded Context Data Models that align with coherent parts of the business processes and the definitions of associated business entities
B) Build distinct data models for each API to follow established micro-services and Agile API-centric practices
C) Build all API data models using XML schema to drive consistency and reuse across the organization
D) Build one centralized Canonical Data Model (Enterprise Data Model) that unifies all the data types from all three business processes, ensuring the data model is consistent and non-redundant
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
✅ Why A is correct
This scenario perfectly matches MuleSoft’s recommended API-led connectivity + Domain-Driven Design (DDD) approach.
You are told that:
* There are multiple LOBs (siloed teams)
* Each LOB owns its own business processes
* Some business entities are shared, but not all
* Teams are independent and have separate budgets
In this situation, the most effective and scalable approach is to define bounded context data models, where:
* Each bounded context aligns with a business capability or domain
* Data models are locally consistent and owned by a team
* Shared concepts are reused intentionally, not forced globally
* APIs remain loosely coupled while avoiding unnecessary duplication
This directly matches MuleSoft’s recommended practice for Process APIs and System APIs when multiple business domains coexist.
❌ Why the other options are incorrect
B. Build distinct data models for each API
❌ Leads to maximum duplication, inconsistent semantics, and higher maintenance costs
❌ Violates reuse principles encouraged by API-led connectivity
C. Use XML schema for consistency
❌ Technology choice (XML vs JSON) does not solve modeling or governance problems
❌ Modern MuleSoft APIs typically use JSON/REST, not XML schemas
D. Build a single Enterprise Canonical Data Model
❌ Too rigid and expensive
❌ Slows delivery and innovation
❌ Often becomes a bottleneck and fails in federated organizations
MuleSoft explicitly discourages forcing a single enterprise-wide canonical model unless the organization is extremely mature and centralized.
🧠 Exam takeaway
Bounded Contexts strike the balance between reuse and autonomy.
They reduce redundancy without creating organizational bottlenecks.
How are an API implementation, API client, and API consumer combined to invoke and process an API?
A. The API consumer creates an API implementation, which receives API invocations from an API such that they are processed for an API client
B. The API client creates an API consumer, which receives API invocations from an API such that they are processed for an API implementation
C. The ApI consumer creates an API client, which sends API invocations to an API such that they are processed by an API implementation
D. The ApI client creates an API consumer, which sends API invocations to an API such that they are processed by an API implementation
Explanation:
Let’s break down the key roles:
API Consumer
The entity (e.g., a business unit or external system) that needs to use the API
API Client
The actual software (e.g., app, script, integration) that sends requests to the API
API
The interface that defines how clients interact with the backend logic
API Implementation
The backend logic or service that processes the API requests and returns responses
🔄 Flow of Invocation:
API Consumer decides to use an API.
They create or configure an API client (e.g., a Mule flow, Postman collection, or frontend app).
The API client sends requests to the API endpoint.
The API implementation receives and processes the request, returning a response.
This is a classic separation of concerns in API-led architecture:
Consumers don’t directly interact with implementations.
Clients are the bridge between consumers and APIs.
❌ Why the Other Options Are Incorrect:
A Reverses the relationship — consumers don’t create implementations.
B Misrepresents the flow — clients don’t create consumers.
D Incorrect actor relationships — clients don’t create consumers, and the flow is reversed.
🔗 Reference:
MuleSoft API-led Connectivity Overview
MuleSoft Docs – API Manager and Client Interaction
A client has several applications running on the Salesforce service cloud. The business requirement for integration is to get daily data changes from Account and Case
Objects. Data needs to be moved to the client's private cloud AWS DynamoDB instance as a single JSON and the business foresees only wanting five attributes from the
Account object, which has 219 attributes (some custom) and eight attributes from the Case Object.
What design should be used to support the API/ Application data model?
A. Create separate entities for Account and Case Objects by mimicking all the attributes in SAPI, which are combined by the PAPI and filtered to provide JSON output containing 13 attributes.
B. Request client’s AWS project team to replicate all the attributes and create Account and Case JSON table in DynamoDB. Then create separate entities for Account and Case Objects by mimicking all the attributes in SAPI to transfer ISON data to DynamoD for respective Objects
C. Start implementing an Enterprise Data Model by defining enterprise Account and Case Objects and implement SAPI and DynamoDB tables based on the Enterprise Data Model,
D. Create separate entities for Account with five attributes and Case with eight attributes in SAPI, which are combined by the PAPI to provide JSON output containing 13 attributes.
Explanation:
Why this design is best:
The business only needs 13 fields total (5 from Account, 8 from Case). Modeling and moving all 219 Account attributes creates unnecessary coupling, payload bloat, and future maintenance risk.
In API-led connectivity, a good practice is to expose only what consumers need (and what you intend to support as part of the contract). That keeps the API contract stable, improves performance, and reduces downstream change impact.
A clean layering approach here is:
System API (SAPI): exposes the minimal, required fields from Salesforce objects (Account, Case) that are needed for the integration use case.
Process API (PAPI): orchestrates/joins the data and produces the single combined JSON destined for DynamoDB.
Why the other options are not as good:
A ❌ Mimicking all Salesforce attributes in the SAPI then filtering later makes the SAPI tightly coupled to Salesforce’s full object schema and increases payload/maintenance for no business value.
B ❌ Replicating all attributes into DynamoDB is even worse—creates unnecessary storage/model complexity and contradicts the requirement that the business only foresees needing a small subset.
C ❌ Building an Enterprise Data Model is a large, long-term initiative. For a targeted daily extract of a small set of fields, it’s overkill and slows delivery.
Bottom line:
Build APIs around the required contract. Model the 5 + 8 fields in the SAPI and let the PAPI compose the single JSON output.
A set of tests must be performed prior to deploying API implementations to a staging environment. Due to data security and access restrictions, untested APIs cannot be granted access to the backend systems, so instead mocked data must be used for these tests. The amount of available mocked data and its contents is sufficient to entirely test the API implementations with no active connections to the backend systems. What type of tests should be used to incorporate this mocked data?
A. Integration tests
B. Performance tests
C. Functional tests (Blackbox)
D. Unit tests (Whitebox)
Explanation:
MUnit (MuleSoft’s test framework) is designed to run unit tests that mock processors/connectors so your flows can be fully validated offline with predetermined data. This matches the requirement: no access to secured backends, yet complete behavior coverage using mocked payloads/responses.
Eliminate others:
A. Integration tests — Typically verify interactions with real downstream systems; using only mocks defeats the purpose of integration testing.
B. Performance tests — Focus on throughput/latency under load, usually against production-like environments and data, not mocked-only setups. (Not aligned with the stated goal.)
C. Functional tests (Blackbox) — Blackbox/API functional monitoring validates a deployed API and its live dependencies based on inputs/outputs, without mocking or altering internals—the opposite of this scenario.
References:
MUnit Overview — MuleSoft’s framework for unit/integration tests.
MUnit Mock When — How to mock processors/connectors in tests.
Mocking resources for tests — Using DataWeave/resources to feed mocked data.
API Functional Monitoring (BAT) — Blackbox tests hit live dependencies; no mocking.
What is a best practice when building System APIs?
A. Document the API using an easily consumable asset like a RAML definition
B. Model all API resources and methods to closely mimic the operations of the backend system
C. Build an Enterprise Data Model (Canonical Data Model) for each backend system and apply it to System APIs
D. Expose to API clients all technical details of the API implementation's interaction wifch the backend system
Explanation:
When building System APIs in the context of MuleSoft’s API-led connectivity, the goal is to create reusable, secure, and well-governed interfaces that abstract the complexities of backend systems (e.g., ERPs, databases, legacy systems) and provide standardized access to their data and functionality. System APIs are the foundation of the API-led connectivity model, and best practices focus on ensuring they are reusable, maintainable, and easy to consume by other layers (e.g., Process APIs) or developers.
Why Option A is Correct:
Documentation with RAML: A key best practice for System APIs is to provide clear, standardized, and consumable documentation to enable reuse and ease of integration. RAML (RESTful API Modeling Language) is MuleSoft’s preferred specification for defining APIs in a structured, human- and machine-readable format. It allows developers to describe API resources, methods, parameters, and responses clearly, which aligns with MuleSoft’s emphasis on discoverability and self-service in Anypoint Platform (e.g., via Anypoint Exchange).
Benefits: RAML documentation promotes reusability, reduces onboarding time for developers, and supports governance by making APIs discoverable in tools like Anypoint Exchange. It abstracts implementation details, making it easier for consumers to understand and use the API without needing to know the backend system’s complexities.
MuleSoft Alignment: MuleSoft’s best practices, as outlined in their documentation and training, emphasize publishing APIs with clear specifications (like RAML or OpenAPI) to Anypoint Exchange to ensure they are consumable and reusable across the organization.
Why Not the Other Options?
B. Model all API resources and methods to closely mimic the operations of the backend system:
Incorrect. A key principle of System APIs is to abstract the backend system’s complexity, not mirror it. Directly mimicking backend operations (e.g., exposing raw database queries or legacy system methods) defeats the purpose of decoupling the API consumer from the backend. Instead, System APIs should expose simplified, standardized interfaces that hide backend intricacies and provide a consistent contract for consumers. For example, a System API for a Salesforce backend should expose logical resources (e.g., /accounts) rather than replicating Salesforce’s internal API methods.
C. Build an Enterprise Data Model (Canonical Data Model) for each backend system and apply it to System APIs:
Incorrect. While a canonical data model (CDM) is valuable for standardizing data across APIs (typically in Process APIs or across the enterprise), it is not a best practice to create a CDM for each backend system for System APIs. System APIs are designed to expose the data and functionality of a specific backend system in a simplified way, often reflecting the backend’s native data model (translated into a RESTful structure). A CDM is more appropriate for Process APIs, which orchestrate data across multiple systems and require a unified data model to ensure consistency.
D. Expose to API clients all technical details of the API implementation’s interaction with the backend system:
Incorrect. Exposing technical details (e.g., how the API interacts with the backend’s protocols, queries, or internal logic) violates the principle of abstraction in API-led connectivity. System APIs should shield consumers from backend complexities, providing a clean, RESTful interface that focuses on business-relevant resources and operations. Exposing implementation details makes the API harder to consume, reduces flexibility, and tightly couples consumers to the backend, which undermines reusability and maintainability.
Reference:
MuleSoft Documentation: API-led Connectivity – System APIs – Emphasizes that System APIs abstract backend systems and require clear, consumable interfaces.
MuleSoft Anypoint Exchange: Best Practices for API Design – Highlights the importance of documenting APIs with RAML or OpenAPI for discoverability and reuse in Anypoint Exchange.
MuleSoft Training: MuleSoft Certified Platform Architect – Level 1 (MCPA) course materials stress that System APIs should be well-documented, reusable, and abstract backend complexity, with RAML as a standard for defining API contracts.
RAML Specification: RAML.org – Details how RAML provides a structured, consumable way to define APIs, aligning with MuleSoft’s best practices.
Refer to the exhibit.
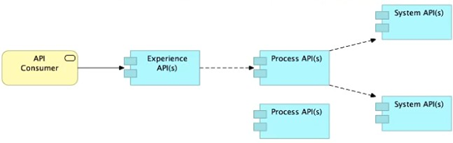
What is the best way to decompose one end-to-end business process into a collaboration of Experience, Process, and System APIs?
A) Handle customizations for the end-user application at the Process API level rather than the Experience API level
B) Allow System APIs to return data that is NOT currently required by the identified Process or Experience APIs
C) Always use a tiered approach by creating exactly one API for each of the 3 layers (Experience, Process and System APIs)
D) Use a Process API to orchestrate calls to multiple System APIs, but NOT to other Process APIs
A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
Noun-Based vs. Task-Based: System APIs should be designed around "Nouns" (e.g., Customer, Order, Product) rather than a specific "Task" or project requirement.
Maximizing Reuse: If a System API only returns the 3 fields required by a current mobile app project, it will likely need to be modified when a future web app project needs 5 fields from the same system.
Domain Modeling: By allowing a System API to return a broader, more complete representation of an entity (e.g., a full Customer profile), it becomes a highly reusable "building block" that multiple Process APIs can consume without requiring constant changes to the System layer.
Separation of Concerns: The System API focuses on the system of record, while the Process API and Experience API handle the specific filtering, transformation, and tailoring of that data for a particular use case.
🔴 Incorrect Answers
A) Handle customizations... at the Process API level: This is incorrect. Customizations for a specific application (like formatting for a smartwatch vs. a desktop browser) should be handled at the Experience API level. The Process layer should remain agnostic of the target device to ensure the business logic can be reused across different channels.
C) Exactly one API for each of the 3 layers: API-led connectivity is not a rigid "three-tier" requirement for every flow. It is an architectural philosophy. Some processes might call multiple System APIs, while others might skip the Process layer if no orchestration is needed. Forcing a 1:1:1 ratio leads to "pass-through" APIs that add latency without adding value.
D) Process API to orchestrate calls to System APIs, but NOT to other Process APIs: In complex architectures, Process APIs can and should invoke other Process APIs to handle sub-processes (e.g., an "Order Fulfillment" Process API might call an "Inventory Validation" Process API). This promotes modularity and prevents the creation of "God-like" monolithic Process APIs.
📚 Reference
MuleSoft Documentation: API-led Connectivity Architecture
Key Concept:
Designing for Reusability. Success in the MuleSoft model is measured by the "Reuse Ratio." Designing System APIs to be comprehensive "System of Record" interfaces ensures that Central IT can provide a stable foundation that LOB teams can build upon independently.
True or False. We should always make sure that the APIs being designed and developed are self-servable even if it needs more man-day effort and resources.
A. FALSE
B. TRUE
Explanation
In MuleSoft’s API-led connectivity approach, self-servable APIs are a cornerstone of scalable, agile integration architecture. Making APIs discoverable, reusable, and easy to consume — even if it requires more initial effort — pays off significantly in the long run.
Here’s why:
🔍 Discoverability: APIs that are well-documented and published to Anypoint Exchange allow teams to find and reuse them without reinventing the wheel.
🔄 Reusability: Self-servable APIs reduce duplication and promote consistency across projects and business units.
🚀 Agility: Teams can build faster when they don’t need to wait for custom integrations or deep backend knowledge.
🛠️ Governance & Maintainability: Standardized, self-servable APIs are easier to monitor, secure, and evolve.
Even if it takes more man-days upfront to design, document, and publish APIs properly, the total cost of ownership (TCO) decreases over time due to reduced integration effort, fewer bugs, and faster onboarding.
🔗 Reference:
MuleSoft – API Design Best Practices
MuleSoft – Anypoint Exchange and Self-Service
Refer to the exhibit.
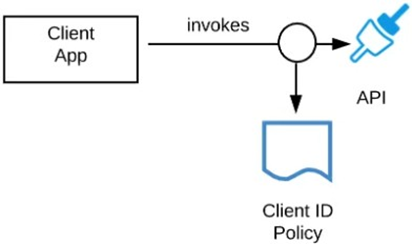
A developer is building a client application to invoke an API deployed to the STAGING environment that is governed by a client ID enforcement policy.
What is required to successfully invoke the API?
A. The client ID and secret for the Anypoint Platform account owning the API in the STAGING environment
B. The client ID and secret for the Anypoint Platform account's STAGING environment
C. The client ID and secret obtained from Anypoint Exchange for the API instance in the STAGING environment
D. A valid OAuth token obtained from Anypoint Platform and its associated client ID and secret
Explanation:
This question tests the practical steps for a client application to authenticate when calling an API protected by a Client ID Enforcement Policy. The process is part of MuleSoft's API consumer onboarding workflow.
Correct Process:
API Publisher Action: In the STAGING environment of API Manager, the API is configured with a Client ID Enforcement policy. The publisher must also define one or more "applications" in API Manager or Exchange that represent the consuming client apps.
Consumer Action (Developer): The developer of the client application goes to the API's portal page in Anypoint Exchange, navigates to the STAGING environment, and requests access. Upon approval, they can view or generate unique client_id and client_secret credentials specifically for their application to access that API instance in that environment.
API Invocation: The client application includes these environment-specific and API-specific credentials in the HTTP request, typically as a Basic Auth header (Authorization: Basic <base64(client_id:client_secret)>) or as parameters.
These credentials are tied to the specific API instance in a specific environment (STAGING), not to a general platform account.
Why the Other Options Are Incorrect:
A. The client ID and secret for the Anypoint Platform account owning the API: This refers to the platform account credentials used to log into Anypoint Platform. These are not for API authentication and should never be embedded in a client application.
B. The client ID and secret for the Anypoint Platform account's STAGING environment: There is no such thing as a general "account environment" credential. Credentials are issued per API application contract, not per environment for an entire account.
D. A valid OAuth token obtained from Anypoint Platform and its associated client ID and secret: This describes the OAuth 2.0 Client Credentials grant flow. While one valid method, it is not the only requirement and is more specific than needed. The Client ID Enforcement policy can be satisfied by either:
Direct Basic Auth (using the client_id and client_secret as username/password – Option C).
OAuth 2.0 Token (where the client uses its client_id/secret to first get a token from Anypoint Platform, then sends the token).
The question asks what is "required to successfully invoke." The fundamental requirement is the client_id and client_secret pair issued for that API in STAGING. Option C is the direct and most complete answer covering the credential source. Option D describes a specific authentication mechanism using those credentials.
Reference:
MuleSoft Documentation - "Client ID Enforcement Policy": Explains that to call an API with this policy, a consumer must "supply the client ID and client secret that they receive when they register their application in Anypoint Exchange or API Manager."
API Consumer Onboarding Flow: The standard process shows a developer requesting access in Exchange, getting approved, and receiving credentials that are specific to the API and environment.
| Page 1 out of 16 Pages |
| 12345 |
Our new timed 2026 Salesforce-MuleSoft-Platform-Architect practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified MuleSoft Platform Architect - Mule-Arch-201 exam?
We've launched a brand-new, timed Salesforce-MuleSoft-Platform-Architect practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-MuleSoft-Platform-Architect practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved