Total 273 Questions
Last Updated On : 27-Jul-2026
Preparing with Salesforce-MuleSoft-Platform-Integration-Architect practice test 2026 is essential to ensure success on the exam. It allows you to familiarize yourself with the Salesforce-MuleSoft-Platform-Integration-Architect exam questions format and identify your strengths and weaknesses. By practicing thoroughly, you can maximize your chances of passing the Salesforce certification 2026 exam on your first attempt. Start with free Salesforce Certified MuleSoft Platform Integration Architect - Mule-Arch-202 sample questions or use the timed simulator for full exam practice. Surveys from different platforms and user-reported pass rates suggest Salesforce Certified MuleSoft Platform Integration Architect - Mule-Arch-202 practice exam users are ~30-40% more likely to pass.

A payment processing company has implemented a Payment Processing API Mule application to process credit card and debit card transactions, Because the Payment Processing API handles highly sensitive information, the payment processing company requires that data must be encrypted both In-transit and at-rest. To meet these security requirements, consumers of the Payment Processing API must create request message payloads in a JSON format specified by the API, and the message payload values must be encrypted. How can the Payment Processing API validate requests received from API consumers?
A. A Transport Layer Security (TLS) - Inbound policy can be applied in API Manager to decrypt the message payload and the Mule application implementation can then use the JSON Validation module to validate the JSON data
B. The Mule application implementation can use the APIkit module to decrypt and then validate the JSON data
C. The Mule application implementation can use the Validation module to decrypt and then validate the JSON data
D. The Mule application implementation can use DataWeave to decrypt the message payload and then use the JSON Scheme Validation module to validate the JSON data
Explanation
The critical detail is that the message payload values must be encrypted. This means that even though the request is sent over TLS (encrypting the data in-transit), the JSON body itself is also encrypted. API Manager policies and standard validation modules operate on the HTTP request payload as it is received.
Why D is Correct:
Decryption First:
The encrypted payload received by the Mule application is just a ciphertext string. Before it can be validated as JSON, it must be decrypted. This decryption logic requires a cryptographic key and algorithm that is known to both the consumer and the provider. This custom decryption logic is best implemented in a DataWeave script or a Java component within the main Mule application flow.
Validation Second:
Once the payload is decrypted into a plaintext JSON string, it can then be validated against the expected JSON schema. The Validation Module in MuleSoft provides a "JSON Schema Validation" scope that is perfect for this task. It ensures the structure and data types of the JSON conform to the API's specification.
This two-step process (Decrypt -> Validate) must be implemented within the Mule application's flow logic, as it requires knowledge of the specific encryption keys and algorithms used.
Why the Other Options are Incorrect:
A. A Transport Layer Security (TLS) - Inbound policy can be applied in API Manager to decrypt the message payload...
Incorrect. A TLS policy in API Manager ensures the transport channel (HTTPS) is secure. It does not decrypt a custom-encrypted payload within the HTTP body. It only decrypts the HTTPS transmission itself. The encrypted JSON payload remains encrypted when it reaches the Mule application.
B. The Mule application implementation can use the APIkit module to decrypt and then validate the JSON data
Incorrect. The APIkit module is primarily for scaffolding REST APIs from a RAML specification and routing requests. It does not have built-in functionality for decrypting custom-encrypted payloads. Its validation is also based on the API specification and happens before any custom business logic, meaning it would try to validate the encrypted string as if it were JSON, which would fail.
C. The Mule application implementation can use the Validation module to decrypt and then validate the JSON data
Incorrect. The Validation module is only for validation (checking data against rules). It does not have any capabilities for decryption. This option incorrectly attributes a decryption function to the Validation module.
Summary
The key takeaway is that payload-level encryption is different from transport-level encryption (TLS). Validating an encrypted payload requires a custom decryption step within the application flow before any standard validation can occur. DataWeave is the appropriate tool for the transformation/decryption step, followed by the Validation module for schema checks.
Reference
MuleSoft Documentation: Validation Module - Details how to use the JSON Schema Validation scope to validate a payload against a schema.
MuleSoft Documentation: DataWeave Crypto Functions - While not the only way, DataWeave provides functions for encryption/decryption, illustrating that this logic is implemented within data transformation steps.
Why would an Enterprise Architect use a single enterprise-wide canonical data model (CDM) when designing an integration solution using Anypoint Platform?
A. To reduce dependencies when integrating multiple systems that use different data formats
B. To automate Al-enabled API implementation generation based on normalized backend databases from separate vendors
C. To leverage a data abstraction layer that shields existing Mule applications from nonbackward compatible changes to the model's data structure
D. To remove the need to perform data transformation when processing message payloads in Mule applications
Explanation:
A canonical data model (CDM) is a standardized, enterprise-wide data format that acts as a common language for integration. The primary purpose is to decouple systems.
Why A is correct:
Without a CDM, integrating multiple systems (e.g., Salesforce, SAP, a legacy database) would require building point-to-point transformations for every possible connection (a "spaghetti" integration). This creates a tight coupling and a maintenance nightmare. A CDM simplifies this to a many-to-one relationship: each system only needs a transformation to and from the CDM. This dramatically reduces dependencies between systems, as a change in one system's data format only requires an update to its single transformation map to the CDM, not to every other system it communicates with.
Let's examine why the other options are incorrect:
B. To automate Al-enabled API implementation generation...:
This is incorrect. While MuleSoft has tools for accelerating development (like the API specification import), the use of a CDM is a strategic design pattern, not a tool for automating implementation based on existing database schemas. The goal of a CDM is often to create a model that is independent of any specific backend system's schema.
C. To leverage a data abstraction layer that shields existing Mule applications from non-backward compatible changes...:
This is a very good secondary benefit and is related to the correct answer, but it is not the primary reason. The abstraction layer (the CDM) does provide shielding, but its core purpose is to enable communication and reduce dependencies between all systems (A), which inherently provides the benefit described in C. Option A is the more fundamental and comprehensive reason.
D. To remove the need to perform data transformation...:
This is incorrect and unrealistic. The use of a CDM does not remove the need for transformation; it standardizes and centralizes it. Mule applications will still need to transform data from a system-specific format into the CDM and from the CDM into the target system's format. The transformation logic is still required, but it becomes more manageable and reusable.
References/Key Concepts:
Canonical Data Model Pattern:
This is a well-established Enterprise Integration Pattern (EIP). Its main advantage is reducing the number of required translators from N*(N-1) to 2*N, where N is the number of systems.
Loose Coupling:
A core principle of good integration architecture. Using a CDM is a primary method for achieving loose coupling between applications.
API-Led Connectivity:
The concept of a CDM aligns closely with the System API layer, which provides a canonical interface to a backend system, shielding the rest of the integration landscape from its peculiarities.
A leading eCommerce giant will use MuleSoft APIs on Runtime Fabric (RTF) to process
customer orders. Some customer-sensitive information, such as credit card information, is
required in request payloads or is included in response payloads in some of the APIs.
Other API requests and responses are not authorized to access some of this customer sensitive information but have been implemented to validate and transform based on the
structure and format of this customer-sensitive information (such as account IDs, phone
numbers, and postal codes).
What approach configures an API gateway to hide sensitive data exchanged between API
consumers and API implementations, but can convert tokenized fields back to their original
value for other API requests or responses, without having to recode the API
implementations?
Later, the project team requires all API specifications to be augmented with an additional
non-functional requirement (NFR) to protect the backend services from a high rate of
requests, according to defined service-level.
agreements (SLAs). The NFR's SLAs are based on a new tiered subscription level "Gold",
"Silver", or "Platinum" that must be tied to a new parameter that is being added to the
Accounts object in their enterprise data model.
Following MuleSoft's recommended best practices, how should the project team now
convey the necessary non-functional requirement to stakeholders?
A. Create and deploy API proxies in API Manager for the NFR, change the baseurl in each API specification to the corresponding API proxy implementation endpoint, and publish each modified API specification to Exchange
B. Update each API specification with comments about the NFR's SLAs and publish each modified API specification to Exchange
C. Update each API specification with a shared RAML fragment required to implement the NFR and publish the RAML fragment and each modified API specification to Exchange
D. Create a shared RAML fragment required to implement the NFR, list each API implementation endpoint in the RAML fragment, and publish the RAML fragment to Exchange
Explanation:
The goal is to convey a non-functional requirement (an SLA-based rate limiting policy) within the API specification itself, following MuleSoft's design-first, contract-driven best practices. The specification should be the single source of truth for both functional and non-functional aspects of the API.
Let's evaluate the options:
A. Create and deploy API proxies... change the baseurl...:
This is an incorrect approach for conveying the requirement. This option describes an implementation step (creating proxies in API Manager) rather than a design step. The question asks how to "convey the necessary non-functional requirement to stakeholders." The way to convey the requirement is through the API contract (the specification), not by implementing it and then changing the endpoint URL. Stakeholders (like API consumers) need to understand the SLA before implementation.
B. Update each API specification with comments...:
This is a poor practice. While adding comments to the RAML might seem logical, comments are not a standardized, machine-readable way to define API contracts. They are informal and cannot be easily parsed or enforced by tools. MuleSoft's best practice is to use the formal, structured elements of the API specification.
C. Update each API specification with a shared RAML fragment...:
This is the correct answer. RAML fragments (specifically, Extension Fragments or Libraries containing traits or resource types) are the idiomatic way to extend an API specification with reusable functionality, including policies.
You can create a shared RAML fragment that defines a trait representing the rate-limiting SLA. This trait can include descriptive information about the "Gold," "Silver," and "Platinum" tiers.
This trait is then referenced (applied) within each API specification that requires this NFR. This makes the SLA a formal, discoverable part of the API contract.
Publishing both the shared fragment and the updated specifications to Exchange ensures all stakeholders have a clear, consistent, and reusable definition of the NFR.
D. Create a shared RAML fragment... list each API implementation endpoint in the RAML fragment...:
This is incorrect and architecturally flawed. A RAML fragment should define reusable contracts (types, traits, resource types), not contain a list of implementation endpoints. The endpoint URLs are specific to each API environment (dev, prod) and should be managed in the API Manager, not hardcoded into a shared, design-time fragment. This approach creates tight coupling and is not maintainable.
References:
MuleSoft Documentation: API Design - Using Fragments - RAML fragments are promoted as the best practice for reusability and modularity in API design.
MuleSoft Documentation: Defining Policies in Design Center - While policies are applied in API Manager, the intent and description of SLA-based policies can be conveyed in the design phase using traits within the API specification or fragments.
Key Takeaway: To formally convey non-functional requirements like SLAs in an API contract, MuleSoft's best practice is to use reusable RAML fragments (traits). This makes the requirements a first-class, machine-readable part of the API specification, ensuring clarity for all stakeholders and promoting consistency across multiple APIs.
What is true about automating interactions with Anypoint Platform using tools such as Anypoint Platform REST API's, Anypoint CLI or the Mule Maven plugin?
A. By default, the Anypoint CLI and Mule Maven plugin are not included in the Mule runtime
B. Access to Anypoint Platform API;s and Anypoint CLI can be controlled separately thruough the roles and permissions in Anypoint platform, so that specific users can get access to Anypoint CLI while others get access to the platform API's
C. Anypoint Platform API's can only automate interactions with CloudHub while the Mule maven plugin is required for deployment to customer hosted Mule runtimes
D. API policies can be applied to the Anypoint platform API's so that only certain LOS's has access to specific functions
Explanation
The question asks about automating interactions with Anypoint Platform using tools such as Anypoint Platform REST APIs, Anypoint CLI, or the Mule Maven Plugin, and seeks to identify the true statement among the provided options. Automating interactions with Anypoint Platform typically involves tasks like deploying applications, managing APIs, or querying runtime status in CI/CD pipelines or administrative workflows. Let’s evaluate each option based on MuleSoft’s architecture and best practices.
Analysis of Options
A. By default, the Anypoint CLI and Mule Maven plugin are not included in the Mule runtime:
Correct:
The Mule runtime is the core execution engine for Mule applications, responsible for processing flows and handling integrations. It does not include the Anypoint CLI or Mule Maven Plugin by default, as these are external tools:
Anypoint CLI:
A standalone Node.js-based tool installed separately on a developer’s machine or CI/CD server (e.g., via npm install -g anypoint-cli). It interacts with Anypoint Platform via REST APIs but is not part of the Mule runtime.
Mule Maven Plugin:
A Maven plugin added to a Mule project’s pom.xml file for build and deployment tasks. It is not bundled with the Mule runtime and must be configured separately in the development environment.
Why it’s True:
These tools are designed for development, deployment, and management tasks outside the runtime’s scope. The Mule runtime focuses on executing application logic, not providing CLI or build capabilities.
B. Access to Anypoint Platform APIs and Anypoint CLI can be controlled separately through the roles and permissions in Anypoint Platform, so that specific users can get access to Anypoint CLI while others get access to the Platform APIs:
Incorrect:
Access to Anypoint Platform REST APIs and Anypoint CLI is controlled through the same roles and permissions in Anypoint Platform’s Role-Based Access Control (RBAC) system. The Anypoint CLI uses the Platform APIs under the hood, authenticating with the same user credentials (e.g., username/password or connected app client ID/secret). Permissions are assigned at the API level (e.g., Runtime Manager, API Manager), not separately for the CLI or APIs.
Why it’s False:
You cannot grant access to the CLI without granting access to the underlying APIs it calls, as the CLI is essentially a wrapper for the REST APIs. For example, a user with the “Deployer” role in Runtime Manager can use both the CLI and APIs to deploy applications, and there’s no mechanism to isolate CLI access from API access.
Reference:
MuleSoft Documentation:Anypoint Platform RBAC explains that permissions are tied to API endpoints, not the tools used to access them.
C. Anypoint Platform APIs can only automate interactions with CloudHub while the Mule Maven Plugin is required for deployment to customer-hosted Mule runtimes:
Incorrect:
The Anypoint Platform REST APIs support automation for various components, including CloudHub, Runtime Fabric, and customer-hosted Mule runtimes (via Runtime Manager APIs). They are not limited to CloudHub. Similarly, the Mule Maven Plugin supports deployment to both CloudHub and customer-hosted runtimes (e.g., using the mule:deploy goal with appropriate configurations).
Why it’s False:
Both tools can interact with CloudHub and customer-hosted runtimes. For example:
D. API policies can be applied to the Anypoint Platform APIs so that only certain LOS’s has access to specific functions:
Incorrect:
The term “LOS’s” is unclear but likely a typo for “users” or “lines of service.” Regardless, Anypoint Platform APIs (e.g., Runtime Manager, API Manager APIs) are not managed by applying API policies like those used for Mule application APIs (e.g., rate limiting, client ID enforcement). Instead, access to Platform APIs is controlled via RBAC and connected app credentials (client ID/secret) in Anypoint Platform. Policies are applied to Mule APIs in API Manager, not to the Platform APIs themselves.
Why it’s False:
Platform APIs are secured through OAuth 2.0 or basic authentication, not API Manager policies. For example, a connected app is granted scopes (e.g., manage_apis, deploy_applications) to control access, not policies like rate limiting.
Reference:
MuleSoft Documentation: Connected Apps explains Platform API security via RBAC and OAuth, not API policies.
Reference:
MuleSoft Documentation:
Anypoint CLI : Describes CLI as a standalone tool for automating Platform interactions, not included in the Mule runtime.
MuleSoft Documentation:
Mule Maven Plugin : Confirms the plugin is a separate Maven dependency, not part of the runtime.
MuleSoft Documentation:
Anypoint Platform APIs : Details API usage for automation across CloudHub and customer-hosted runtimes.
MuleSoft Documentation:
Access Management : Explains how permissions control access to APIs and CLI, not separate for each tool.
Final Answer
The true statement about automating interactions with Anypoint Platform using tools like Anypoint Platform REST APIs, Anypoint CLI, or the Mule Maven Plugin is A. By default, the Anypoint CLI and Mule Maven plugin are not included in the Mule runtime. These tools are external to the Mule runtime and are designed for development, deployment, and management tasks.
Refer to the exhibit.
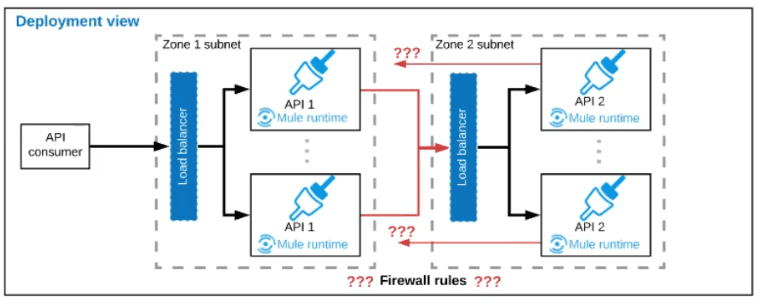
A business process involves two APIs that interact with each other asynchronously over
HTTP. Each API is implemented as a Mule application. API 1 receives the initial HTTP
request and invokes API 2 (in a fire and forget fashion) while API 2, upon completion of the
processing, calls back into API l to notify about completion of the asynchronous process.
Each API Is deployed to multiple redundant Mule runtimes and a separate load balancer,
and is deployed to a separate network zone.
In the network architecture, how must the firewall rules be configured to enable the above
Interaction between API 1 and API 2?
A. To authorize the certificate to be used both APIs
B. To enable communication from each API’s Mule Runtimes and Network zone to the load balancer of the other API
C. To open direct two-way communication between the Mule Runtimes of both API’s
D. To allow communication between load balancers used by each API
Explanation:
The key to understanding this scenario is the architecture described: each API has its own set of Mule runtimes behind a load balancer and in a separate network zone. This is a standard design for security and scalability, often resembling a DMZ (Demilitarized Zone) setup.
Let's trace the communication flow:
Initial Request (API 1 -> API 2):
The initial request comes from an external client to API 1's load balancer. API 1's logic then needs to call API 2. This call should not go directly to a specific Mule runtime of API 2. Instead, for high availability and to abstract the internal topology, it should go to API 2's load balancer. The load balancer then routes the request to one of API 2's healthy runtimes.
Callback (API 2 -> API 1):
After processing, API 2 needs to call back to API 1. Similarly, this callback should not go directly to a specific runtime of API 1. It should be sent to API 1's load balancer, which will then route it to an available runtime.
This pattern ensures that the internal architecture of each API (how many runtimes, their IPs) is hidden from the other API, promoting loose coupling and resilience.
Now, let's evaluate the firewall rules needed to support this flow:
A. To authorize the certificate:
This is about authentication, not network connectivity. Firewall rules control IP/port access. While TLS certificates are crucial for security, they operate at a different layer (application layer) once a connection is established. The firewall must first allow the network connection to happen.
B. To enable communication from each API’s Mule Runtimes... to the load balancer of the other API:
This is the correct answer. The firewalls for each network zone must be configured to allow outbound traffic from the Mule runtimes in Zone A to the IP address and port of the load balancer in Zone B, and vice-versa. This allows for the two-way, asynchronous communication via the designated entry points (the load balancers).
C. To open direct two-way communication between the Mule Runtimes of both APIs:
This is an incorrect and poor practice. This would create a tightly coupled "mesh" network where every runtime of API 1 needs to know about every runtime of API 2. It bypasses the load balancers, which are there to provide a single entry point, load distribution, and health checking. This is difficult to manage, less secure, and not scalable.
D. To allow communication between load balancers used by each API:
This is incorrect. The load balancers themselves do not communicate with each other. Communication is always initiated by a Mule runtime through its local load balancer, destined for the other API's load balancer. The load balancers are endpoints, not initiators.
References:
General Networking & DMZ Best Practices: This pattern is standard for secure application integration. The principle is to expose only a single entry point (the load balancer) in a network zone and to control traffic through that point.
Key Takeaway: In a segmented network architecture where services are behind load balancers, firewall rules should be configured to allow application instances to communicate through the official entry point (the load balancer) of the other service's network zone. This maintains the integrity of the network segmentation and leverages the load balancer's role as a single, managed access point.
An organization is creating a Mule application that will be deployed to CloudHub. The Mule application has a property named dbPassword that stores a database user’s password. The organization's security standards indicate that the dbPassword property must be hidden from every Anypoint Platform user after the value is set in the Runtime Manager Properties tab. What configuration in the Mule application helps hide the dbPassword property value in Runtime Manager?
A. Use secure::dbPassword as the property placeholder name and store the cleartext (unencrypted) value in a secure properties placeholder file
B. Use secure::dbPassword as the property placeholder name and store the property encrypted value in a secure properties placeholder file
C. Add the dbPassword property to the secureProperties section of the pom.xml file
D. Add the dbPassword property to the secureProperties section of the mule-artifact.json file
Explanation:
This question tests the knowledge of securing sensitive properties for Mule applications deployed to CloudHub using Runtime Manager. The requirement is to hide the property value from Platform users after it is set in the Runtime Manager UI.
Why D is correct:
The mule-artifact.json file is the deployment descriptor for a Mule application. It contains a secureProperties section. When you list a property name (e.g., dbPassword) in this array, it instructs Runtime Manager to treat that property as sensitive.
Effect:
After you enter the value for dbPassword in the Runtime Manager Properties tab for an application and save it, the value becomes masked (displayed as dots ••••••). This prevents any user with access to Runtime Manager from viewing the cleartext password, thus meeting the security standard.
Let's examine why the other options are incorrect:
A & B. Use secure::dbPassword as the property placeholder name...:
This is incorrect. The secure:: prefix is used for a different purpose: when you want the Mule application to decrypt a value that is already stored in an encrypted format within a properties file. It does not control how the property is displayed or handled within Runtime Manager's UI. The question is about hiding the value in Runtime Manager, not about encrypting it within a file.
C. Add the dbPassword property to the secureProperties section of the pom.xml file:
This is incorrect. The pom.xml file is used by Maven for building the application. While there are Maven plugins for handling secrets, the secureProperties configuration that Runtime Manager recognizes for masking values in the UI is defined in the mule-artifact.json file, not in pom.xml.
References/Key Concepts:
mule-artifact.json:
The official MuleSoft documentation on Application Descriptor explains the secureProperties attribute.
Securing Properties in Runtime Manager:
The specific procedure for securing properties in CloudHub involves adding the property key to the secureProperties array in the mule-artifact.json file.
Property Masking:
This is the key feature. Once a property is designated as secure in the descriptor, its value is masked in the Runtime Manager UI, application logs, and the Anypoint Platform CLI.
Refer to the exhibit: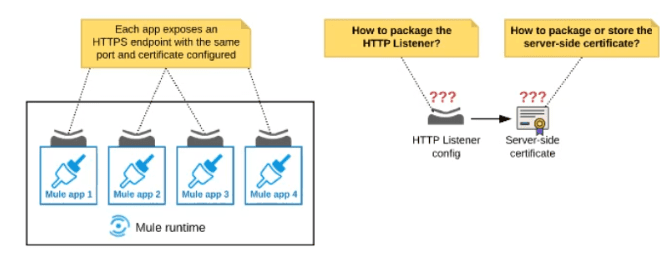
An organization deploys multiple Mule applications to the same customer -hosted Mule
runtime. Many of these Mule applications must expose an HTTPS endpoint on the same
port using a server-side certificate that rotates often.
What is the most effective way to package the HTTP Listener and package or store the
server-side certificate when deploying these Mule applications, so the disruption caused by
certificate rotation is minimized?
A. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint Package the serverside certificate in ALL Mule APPLICATIONS that need to expose an HTTPS endpoint
B. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Store the server-side certificate in a shared filesystem location in the Mule runtime's classpath, OUTSIDE the Mule DOMAIN or any Mule APPLICATION
C. Package an HTTPS Listener configuration In all Mule APPLICATIONS that need to expose an HTTPS endpoint Package the server-side certificate in a NEW Mule DOMAIN project
D. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing It from all Mule applications that need to expose an HTTPS endpoint. Package the serverside certificate in the SAME Mule DOMAIN project Go to Set
Explanation:
The organization deploys multiple Mule applications to the same customer-hosted Mule runtime, and many of these applications must expose an HTTPS endpoint on the same port using a server-side certificate that rotates often. The goal is to minimize disruption caused by certificate rotation while packaging the HTTP Listener configuration and the server-side certificate effectively. Let’s analyze the requirements and evaluate why option B is the most effective solution.
Why Option B is the Best Choice:
HTTPS Listener Configuration in a Mule Domain Project:
A Mule domain project allows centralizing the HTTP Listener configuration (e.g., port, TLS context) shared across multiple Mule applications. By packaging the HTTPS Listener configuration in the domain and referencing it from each application (via the domain attribute in the Mule configuration), all applications can use the same port (e.g., 443) without conflicts.
This approach ensures that changes to the Listener configuration (e.g., port or TLS settings) can be made in one place, reducing maintenance effort.
Server-Side Certificate in a Shared Filesystem Location:
Storing the server-side certificate outside the Mule DOMAIN or any Mule APPLICATION (e.g., in a shared filesystem location like /opt/mule/certs/ within the Mule runtime's classpath) allows the certificate to be updated independently of the deployed artifacts.
When the certificate rotates, the new certificate can be placed in the shared location, and Mule can be configured to reload the TLS context dynamically (e.g., using a file-based keystore or truststore with a reload interval). This avoids redeploying or restarting the applications, minimizing disruption.
The Mule runtime can reference the certificate file path in the domain’s TLS configuration (e.g., via a
Minimizing Disruption:
By separating the certificate from the application and domain artifacts, certificate rotation becomes a runtime operation (e.g., replacing the file and triggering a TLS reload) rather than a deployment operation. This reduces downtime, as applications remain active during the update.
Why Not the Other Options?
A. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Package the server-side certificate in ALL Mule APPLICATIONS that need to expose an HTTPS endpoint:
Drawback:
Packaging the certificate in each Mule application requires redeploying all affected applications whenever the certificate rotates. This introduces significant disruption, as each redeployment involves downtime or rolling restarts, conflicting with the goal of minimizing disruption.
C. Package an HTTPS Listener configuration in all Mule APPLICATIONS that need to expose an HTTPS endpoint. Package the server-side certificate in a NEW Mule DOMAIN project:
Drawback:
Configuring the HTTP Listener in each application leads to port conflicts, as multiple applications cannot bind to the same port (e.g., 443) on the same runtime without a domain. This violates the requirement for a shared port.
Additionally, packaging the certificate in the domain still requires redeploying the domain (and potentially restarting the runtime) when the certificate rotates, causing disruption.
D. Package the HTTPS Listener configuration in a Mule DOMAIN project, referencing it from all Mule applications that need to expose an HTTPS endpoint. Package the server-side certificate in the SAME Mule DOMAIN project:
Drawback:
Packaging the certificate in the domain project means that any certificate rotation requires redeploying the domain project. This triggers a runtime restart or redeployment of the domain, affecting all applications using it and causing downtime—contrary to the goal of minimizing disruption.
While the Listener configuration in the domain is correct, embedding the certificate in the domain artifact reduces flexibility.
References:
MuleSoft Documentation:
Mule Domains:
Explains how domains centralize shared resources like HTTP Listener configurations.
TLS Configuration:
Details configuring TLS with keystores and dynamic reloading.
Deploying to Customer-Hosted Runtimes: Covers deploying multiple applications with shared domains.
Best Practices:
MuleSoft recommends using domains for shared ports and externalizing certificates to avoid redeployment during rotations.
Conclusion:
Option B is the most effective way to package the HTTPS Listener configuration in a Mule domain project and store the server-side certificate in a shared filesystem location outside the domain or applications. This approach ensures port sharing, minimizes disruption during certificate rotation, and aligns with the organization’s deployment model on a customer-hosted Mule runtime.
An integration Mule application is deployed to a customer-hosted multi-node Mule 4 runtime duster. The Mule application uses a Listener operation of a JMS connector to receive incoming messages from a JMS queue. How are the messages consumed by the Mule application?
A. Depending on the JMS provider's configuration, either all messages are consumed by ONLY the primary cluster node or else ALL messages are consumed by ALL cluster nodes
B. Regardless of the Listener operation configuration, all messages are consumed by ALL cluster nodes
C. Depending on the Listener operation configuration, either all messages are consumed by ONLY the primary cluster node or else EACH message is consumed by ANY ONE cluster node
D. Regardless of the Listener operation configuration, all messages are consumed by ONLY the primary cluster node
Explanation:
This question tests the understanding of how a JMS Listener behaves in a clustered environment and the critical configuration that controls it.
The behavior depends entirely on the numberOfConsumers parameter in the JMS Listener configuration:
numberOfConsumers = 1 (Default):
In this mode, the JMS Listener operates in a Primary-Only manner. Only the node that is currently the primary node in the cluster will actively consume messages from the queue. This ensures that each message is processed exactly once. If the primary node fails, a secondary node becomes the new primary and begins consuming messages. This is the safe default for guaranteed, once-and-only-once delivery.
numberOfConsumers > 1 (e.g., equal to the number of cluster nodes):
In this mode, the JMS Listener operates in a Competing Consumers pattern. Each node in the cluster acts as an independent consumer. The JMS provider (like ActiveMQ) ensures that each message is delivered to one, and only one, of the active consumer nodes. This allows for horizontal scaling of message processing, as multiple nodes can process messages from the same queue concurrently.
Let's examine why the other options are incorrect:
A. "...all messages are consumed by ONLY the primary... or else ALL messages are consumed by ALL cluster nodes":
Incorrect. The second scenario is wrong. JMS queues point-to-point messaging semantics guarantee that a message is consumed by only one consumer. It is never sent to all nodes.
B. "...all messages are consumed by ALL cluster nodes":
Incorrect. This describes a publish-subscribe (topic) model, not a queue model. The JMS Listener is connected to a queue, which implements point-to-point messaging.
D. "...all messages are consumed by ONLY the primary cluster node":
Incorrect. This ignores the numberOfConsumers configuration. While it's the default and safest behavior, it is not the only behavior. The configuration can be changed to enable the competing consumers pattern for better throughput.
References/Key Concepts:
JMS Connector Listener Configuration: The numberOfConsumers parameter is key. Setting it to 1 provides failover safety, while setting it to a higher number enables parallel processing.
Clustering and High Availability: Understanding how components behave in a cluster is crucial for the Integration Architect exam.
Enterprise Integration Patterns (EIP): This question directly relates to the Competing Consumers and Message Router patterns.
Refer to the exhibit.
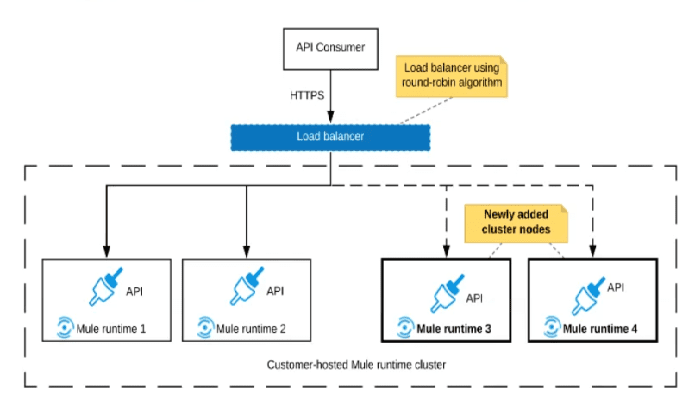
An organization uses a 2-node Mute runtime cluster to host one stateless API
implementation. The API is accessed over HTTPS through a load balancer that uses
round-robin for load distribution.
Two additional nodes have been added to the cluster and the load balancer has been
configured to recognize the new nodes with no other change to the load balancer.
What average performance change is guaranteed to happen, assuming all cluster nodes
are fully operational?
A. 50% reduction in the response time of the API
B. 100% increase in the throughput of the API
C. 50% reduction In the JVM heap memory consumed by each node
D. 50% reduction In the number of requests being received by each node
Explanation
The key to this question is understanding how a stateless API and a round-robin load balancer behave when you add more nodes to a cluster.
Why D is Correct (50% reduction in requests per node):
Initial State:
2 nodes handling the total incoming request load (T). On average, each node handles T/2 requests.
New State:
4 nodes handling the same total incoming request load (T). With a round-robin algorithm, the load balancer will distribute requests evenly across all available nodes. Therefore, on average, each node now handles T/4 requests.
Calculation:
The number of requests per node has gone from T/2 to T/4. This is a 50% reduction ((T/2 - T/4) / (T/2) = 0.5).
Why A is Incorrect (50% reduction in response time):
Response time is determined by the application's logic, database calls, external integrations, and internal processing. Simply adding more nodes does not guarantee a proportional reduction in response time.
If the bottleneck is elsewhere (e.g., a slow database query or an external system with its own rate limit), the response time may not improve at all. Therefore, a specific performance improvement in response time is not guaranteed.
Why B is Incorrect (100% increase in throughput):
Throughput is the total number of requests the entire system can handle per unit of time. While adding nodes increases the capacity for higher throughput, it does not automatically increase the actual throughput.
The actual throughput is limited by the incoming client demand. If the client load (T) remains constant, the total system throughput remains the same; it's just distributed across more nodes. The system now has the potential for 100% higher throughput if the client load increases to match the new capacity, but this is not guaranteed by the scaling action alone.
Why C is Incorrect (50% reduction in JVM heap memory):
Heap memory consumption is driven by the application's behavior and the number of requests it is processing. While each node is now handling fewer requests, which might lead to lower memory usage, this is not a direct or guaranteed correlation.
The memory footprint of the Mule runtime itself and the application's baseline memory usage remain. There is no guarantee of a precise 50% reduction. Memory usage is highly dependent on the specific application and is not directly and linearly proportional to the number of nodes in this way.
Key References
Horizontal Scaling Principle:
The primary outcome of adding more nodes to a stateless system behind a load balancer is the distribution of the workload. The load per node is inversely proportional to the number of nodes, assuming a perfectly even distribution algorithm like round-robin.
MuleSoft Documentation:Clustering and High Availability
This documentation explains how clustering works to distribute load and provide high availability.
Concept: "A cluster is a group of Mule runtime servers that work together to achieve high availability and load balancing."
In summary, the only guaranteed outcome of adding two nodes to a two-node cluster for a stateless API behind a round-robin load balancer is that the average number of requests each individual node must process will be cut in half. The other options relate to performance (throughput, response time) or resource usage (memory), which are influenced by other factors and cannot be guaranteed to change by a specific percentage.
The AnyAirline organization's passenger reservations center is designing an integration solution that combines invocations of three different System APIs (bookFlight, bookHotel, and bookCar) in a business transaction. Each System API makes calls to a single database. The entire business transaction must be rolled back when at least one of the APIs fails. What is the most idiomatic (used for its intended purpose) way to integrate these APIs in near real-time that provides the best balance of consistency, performance, and reliability?
A. Implement eXtended Architecture (XA) transactions between the API implementations Coordinate between the API implementations using a Saga pattern Implement caching in each API implementation to improve performance
B. Implement local transactions within each API implementation Configure each API implementation to also participate in the same eXtended Architecture (XA) transaction Implement caching in each API implementation to improve performance
C. mplement local transactions in each API implementation Coordinate between the API implementations using a Saga pattern Apply various compensating actions depending on where a failure occurs
D. Implement an eXtended Architecture (XA) transaction manager in a Mule application using a Saga pattern Connect each API implementation with the Mule application using XA transactions Apply various compensating actions depending on where a failure occurs
Explanation
The key challenge is coordinating a "business transaction" across three independent System APIs, each with its own database, in a "near real-time" context. The requirement for a rollback if any part fails points towards a need for atomicity, but the distributed nature of the systems makes a traditional ACID transaction impractical.
Why C is Correct (Saga Pattern):
Consistency & Reliability:
The Saga pattern is the standard, idiomatic way to manage long-running business transactions across microservices or distributed systems. Instead of a distributed lock (like XA), it uses a sequence of local transactions. Each local transaction (e.g., bookFlight) is committed immediately.
Compensating Actions:
This is the core of the Saga pattern. If a subsequent step fails (e.g., bookCar fails), the Saga executes pre-defined compensating actions (e.g., cancelFlight, cancelHotel) to undo the previous steps and restore eventual consistency. This directly fulfills the requirement that "the entire business transaction must be rolled back."
Performance:
This approach provides the best performance among reliable options. It avoids the performance overhead and locking duration of a distributed XA transaction, which is significant. Resources (flight seats, hotel rooms) are locked for a much shorter period.
Why A and B are Incorrect (XA Transactions):
Technical Feasibility:
For XA to work, all participating resources (in this case, the three different databases behind the APIs) must be XA-compliant and configured to participate in a global transaction. This is often not the case, especially with external or legacy systems, and is a major architectural constraint.
Performance:
XA transactions use a two-phase commit (2PC) protocol, which involves multiple network round-trips and requires resources to be locked for the duration of the entire transaction. This is a performance bottleneck and is not suitable for "near real-time" systems where responsiveness is key.
Reliability:
A single point of failure in the transaction manager or a network partition during the commit phase can leave resources in an uncertain, locked state. Options A and B are architecturally heavy and often impractical for a distributed API-based architecture.
Why D is Incorrect (Hybrid XA/Saga):
This option mixes two different paradigms incorrectly. A Saga pattern is a coordination pattern that does not use an XA transaction manager. Stating "Implement an eXtended Architecture (XA) transaction manager in a Mule application using a Saga pattern" is a contradiction. Furthermore, "Connect each API implementation... using XA transactions" suffers from all the same drawbacks as A and B.
Key References
Enterprise Integration Pattern: Saga
This is the definitive pattern for managing transactions across multiple services.
Concept: The Saga pattern is the go-to solution for long-lived transactions that span multiple services, using compensating transactions to roll back changes.
| Page 1 out of 28 Pages |
| 123456789 |
Our new timed 2026 Salesforce-MuleSoft-Platform-Integration-Architect practice test mirrors the exact format, number of questions, and time limit of the official exam.
The #1 challenge isn't just knowing the material; it's managing the clock. Our new simulation builds your speed and stamina.
You've studied the concepts. You've learned the material. But are you truly prepared for the pressure of the real Salesforce Certified MuleSoft Platform Integration Architect - Mule-Arch-202 exam?
We've launched a brand-new, timed Salesforce-MuleSoft-Platform-Integration-Architect practice exam that perfectly mirrors the official exam:
✅ Same Number of Questions
✅ Same Time Limit
✅ Same Exam Feel
✅ Unique Exam Every Time
This isn't just another Salesforce-MuleSoft-Platform-Integration-Architect practice questions bank. It's your ultimate preparation engine.
Enroll now and gain the unbeatable advantage of:
Copyright © - All Rights Reserved