Total 64 Questions
Last Updated On : 7-Jul-2025
Preparing with B2C-Commerce-Architect practice test is essential to ensure success on the exam. This Salesforce SP25 test allows you to familiarize yourself with the B2C-Commerce-Architect exam questions format and identify your strengths and weaknesses. By practicing thoroughly, you can maximize your chances of passing the Salesforce certification spring 2025 release exam on your first attempt. Surveys from different platforms and user-reported pass rates suggest B2C-Commerce-Architect practice exam users are ~30-40% more likely to pass.
During discovery, the customer required a feature that is not inducted in the standard Storefront Reference Architecture CSFRA). In order to save budget, the Architect needs to find the quickest way to implement this feature. What is the primary resource the Architect should use to search for an existing community Implementation of the requested feature?
A. Salesforce Commerce Cloud GitHub repository
B. Salesforce Commerce Cloud Trailblazer community
C. Salesforce Trailblazer Portal
D. Salesforce B2C Commerce Documentation
Explanation:
✅ Why A is Correct:
Official place for SFRA source code and community cartridges.
Contains sample integrations and real code examples.
Best starting point for quickly finding existing implementations.
❌ Why Not B (Trailblazer Community):
Great for discussions and questions
Not a code repository
❌ Why Not C (Trailblazer Portal):
Meant for support cases and account management
Not for community code
❌ Why Not D (B2C Commerce Documentation):
Documentation explains features and APIs
Does not include downloadable community cartridges
✅ Recommended Practice:
Check Salesforce Commerce Cloud GitHub for shared code
Saves budget and development time
A client has a single site with multiple domains, locales, and languages. Afterlaunch, there is a need for the client toperform offline maintenance. The client would like to show the same maintenance page for each locale.
Which version of aliases,Json file below will accomplish this task?

A. Option A
B. Option B
C. Option C
D. Option D
Explanation:
✅ Option A
{
"nto.net": "www.nto.net",
"nto.eu": "www.nto.eu",
"nto.event.eu": "www.nto.eu"
}
→ This maps various domains individually to their own or to www.nto.eu. However:
This would serve different hostnames depending on domain.
It doesn’t consolidate everything under a single domain for maintenance.
Not correct.
✅ Option B
{
"www.nto.eu": "www.nto.eu"
}
→ Only maps www.nto.eu → www.nto.eu.
No redirection for other domains (nto.at, nto.de, etc.).
Would leave other domains unreachable during maintenance.
Not correct.
✅ Option C
{
"nto.eu": "www.nto.eu",
"nto.at": "www.nto.at",
"nto.de": "www.nto.de"
}
→ This keeps each country on its own domain.
So www.nto.at would still show a local version, not a universal maintenance page.
Not correct.
✅ Option D
{
"nto.eu": "www.nto.eu",
"nto.at": "www.nto.eu",
"nto.de": "www.nto.eu"
}
✅ This correctly:
Redirects all regional domains (nto.at, nto.de) to one single domain www.nto.eu.
Allows the maintenance page to exist once at www.nto.eu.
Ensures all traffic hits the same maintenance page regardless of locale.
→ This is the correct answer.
✅ Why D is Correct
During maintenance, you want:
One canonical domain for all traffic
Simplified display of the same maintenance page
Avoid maintaining separate maintenance pages for each domain
A developer wants to import the data or different instances.
Which two types of data should the developer consider importing?
(Choose 2 answers)
A. Services
B. Catalog
C. Customers
D. Metadata
E. Sites configurations
Explanation:
When moving data between different Salesforce B2C Commerce instances (e.g. sandbox → staging → production), certain data types are commonly imported/exported to preserve functionality and content.
✅ B. Catalog → Correct
Catalog data includes:
Products
Categories
Prices
Images and assets
This data is absolutely essential for running your storefront. It’s a typical data import/export scenario across environments.
✅ Definitely imported.
✅ C. Customers → Correct
Customer data includes:
Customer accounts
Addresses
Profile attributes
Preferences
It’s common to migrate customer data, especially for testing or staging deployments.
✅ Definitely imported.
❌ Why Not The Other Options
A. Services
“Services” are defined in code and configurations (Service Framework), usually managed via cartridges and BM configurations.
While you might export/import service definitions (e.g. via meta data or replication), they’re not typically called “data imports” like catalog or customer records.
→ Not the typical answer for data import.
D. Metadata
Metadata is very broad:
Includes things like object definitions, site preferences, etc.
While parts of metadata can be imported/exported (e.g. via site import/export), in B2C Commerce, the term “data import” usually focuses on catalogs, customers, prices, promotions.
→ Too broad. Not the best fit for this question.
E. Site configurations
Many site configurations live in Business Manager.
These are often replicated, not imported/exported via standard data files.
Some settings might come via metadata exports, but it’s not typical to call these “data imports.”
→ Not the right answer here.
A developer is checking for Cross Site Scripting (XSS) and found that the quick search is
not escaped (allows inclusion of Javascript) in the following script:
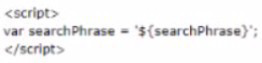
How would the developer resolve this issue?
A. Replace 'with doubleQuote*
B. Use < isprint value = " $ { search Phrase } * encoding-'jshtmr / >
C. Use < isprint value = '$ { searchPhrase } encoding - 'jsblock" / >
D. Use < toprint value = "$ { searchPhrase }" / >
Explanation:
Why?
encoding="jshtml" ensures:
HTML entities are escaped (e.g., < → <).
JavaScript injection is prevented (e.g., " → \x22).
This directly fixes XSS in the quick search.
Why Not Other Options?
❌ A. Replace ' with "
Problem: Simply changing quotes does nothing to escape malicious input.
❌ C. encoding="jsblock"
Problem: jsblock is not a valid encoding type in B2C Commerce.
❌ D.
Problem: No such tag exists in B2C Commerce ISML.
Best Practice:
Always use
encoding="html": Basic HTML escaping.
encoding="jshtml": For JS-in-HTML contexts (e.g., inline scripts).
encoding="url": For URL parameters.
Example Fix:
!-- Before (Vulnerable) -->
<script>var searchTerm = '${searchPhrase}';</script>
!-- After (Secure) -->
<script>var searchTerm = '
During a load test the storefront shows steady but slow performance on all the paces being tested. The Architect opens Pipeline Profiler and sorts the data by *total time" column. The following come as the top Ave items:
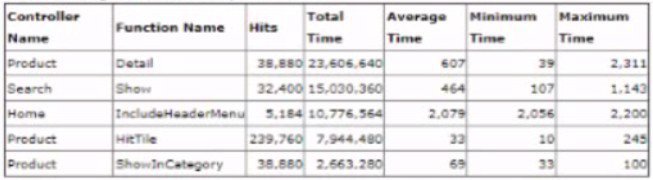
Which controller should the Architect focus on to further investigate the performance issue?
A. Product-HitTile asit has the highest hits duringthe load test.
B. Search Show as this Is one of the key controllers that the customer uses
C. Product-Detail as It has the highest total time and highest maximum time.
D. Home-IncludeHeaderMenu as It has highest average time.
Explanation:
Why?
Average Time (2,079 ms) is critically high compared to other controllers (e.g., Product-Detail at 607 ms).
Total Time (10,776,564 ms) is the 2nd highest, despite having far fewer hits (5,184) than others.
Consistent Slow Performance:
Minimum (2,056 ms) and Maximum (2,200 ms) times are nearly identical, indicating a systemic bottleneck (not sporadic slowness).
Why Not Other Options?
❌ A. Product-HitTile
High hits but low average time (32 ms): Not the root cause of overall slowness.
❌ B. Search-Show
Moderate average time (464 ms): Less urgent than Home-IncludeHeaderMenu.
❌ C. Product-Detail
High total time but lower average time (607 ms): Likely due to high traffic (38,880 hits), not inefficiency.
Root Cause Investigation:
1. Check IncludeHeaderMenu Logic:
Is it making unoptimized API calls (e.g., CMS, categories)?
Does it over-process static data (e.g., menu items)?
2. Cache Analysis:
Ensure menu content is cached (e.g., via iscache).
3. Database Queries:
Audit any slow queries in this controller.
Best Practice:
Optimize high-average-time controllers first—they impact every user request.
Use B2C Commerce Pipeline Profiler to drill into IncludeHeaderMenu’s sub-pipelines.
A developer is validating the pipeline cache and noticed that the PDP page is very low cached. The one parameter is snowing the position on the product fisting page upon checking the site and code. What should the developer adjust in order to improve the page cache hit ratio, keeping in mind that the client is Insisting on the parameter for their analytics?
A. Rework the implementation so it reads the parameter on client-side, passes it to the analytics and exclude It from cache parameters.
B. Add the key to the cache exclude parameters.
C. Rework the Implementation so it doesn’t depend on that parameter.
D. Rework the Implementation so the parameter is not passed In the URL and is read from the URL hash.
Explanation:
The PDP page has a low cache hit ratio because the URL includes a parameter like ?position=5. This creates unique cache entries for every different position value. To fix this without losing analytics data, the parameter should be handled client-side instead of in the URL.
Why A is Correct:
By removing the parameter from the URL and passing it to analytics via JavaScript, the PDP URL stays clean, improving cache hits while still preserving the analytics data.
Example:
// Store position client-side
sessionStorage.setItem('plpPosition', '5');
// Read in analytics script
var pos = sessionStorage.getItem('plpPosition');
analytics.track('PDP View', { position: pos });
Why Not the Other Options:
B: Excluding the parameter from cache would disable caching entirely for those requests, worsening performance.
C: Removing the parameter completely is not acceptable because the client requires it for analytics.
D: Moving the parameter into the URL hash could cause issues with deep linking and still requires significant changes.
A client receives multiple feeds from third parties on the same SFTP location:
• Product prices (sftp: prod/prices)
• Stores information (sftp: prod/stores;
• Product information (sftp: prod/catalog)
• Categories information (sftp: prod/marketing)
• Content (sftp: prod/marketing)
Some of the feeds are placed on sftp multiple times a day, as the information is updated in the source system.
The Architect decides to have only two jobs:
• One that checks and downloads available feeds every hour
• One that imports the files from Webdav once a day before the data replication, using the standards steps available in the Job Framework
Which design is correct for the import Job, taking the steps scope in consideration?
A. - four sibling flows execute steps ki parallel: import products, stores, prices, content- fifth flow executes: import categories- last flow executes steps In sequence: reindex
B. - foursibling flows execute steps in parallel: import products, stores, prices, content- last flow executes steps in sequence import categories, reindex
C. - three siting flows Import steps In parallel: import products, stores, prices- fourth flow executes: import categories- last flow executes steps in sequece:reindex, Import content
D. -Four sibling flows execute steps in parallel: import products, stores, price, content-last flow executes steps in sequence: import:categories, reindex
Explanation:
Why Option B?
✅ Optimal Parallel Processing:
Parallel Imports: Products, stores, prices, and content are processed concurrently (since they are independent).
Sequential Final Steps: Categories are imported after parallel flows (to ensure hierarchy integrity), followed by reindexing (which must run last).
✅ Aligns with Job Framework Best Practices:
Parallelism reduces total job runtime.
Dependencies Managed: Categories (often hierarchical) and reindexing are sequential to avoid conflicts.
Why Not Other Options?
❌ A. Reindex Before Categories Import
Problem: Reindexing before categories are imported leads to incomplete data.
❌ C. Content Import After Reindex
Problem: Content (e.g., marketing assets) should be imported before reindexing to ensure consistency.
❌ D. Same as B, but Typo in Option
Note: If the text is identical, this is likely a duplicate.
Key Design Principles:
Parallelize Independent Tasks:
Prices, stores, products, and content can be imported simultaneously.
Sequential for Dependencies:
Categories (parent/child relationships) and reindexing must run in order.
Reindex Once at the End:
Ensures all data is available before rebuilding search indices.
Example Job Flow:
1. Parallel Flows:
- Flow 1: Import Products
- Flow 2: Import Stores
- Flow 3: Import Prices
- Flow 4: Import Content
2. Sequential Final Steps:
- Flow 5: Import Categories
- Flow 6: Reindex
An Architect to notify by the Business that order conversion dramatically dropped a few hours after go live. Further investigation points out that customers cannot proceed to checkout anymore. The Architect is aware that a custom inventory checks with a third-party API is enforced at the beginning of checkout, and that customers are redirected to the basket page when items are no longer in stock. Which tool can dearly confirm that the problem is indeed caused by the inventory check?
A. Sales Dashboard from Reports and Dashboards
B. Service Status from Business Manager
C. Pipeline Profiler from Business Manager
D. Realtime Report from Reports and Dashboards
Explanation:
✅ Understanding the Scenario
Business reports a dramatic drop in order conversion.
Customers cannot proceed to checkout.
There’s a custom inventory check via third-party API:
Runs at the start of checkout.
If items are out of stock → redirects customer back to basket.
Hence, you need to:
✅ Identify which part of the code is slowing down or failing during checkout.
→ The question is: Which tool clearly confirms that the inventory check is causing the issue?
✅ Why C is Correct → Pipeline Profiler
✅ The correct answer is:
→ C. Pipeline Profiler from Business Manager
Here’s why:
The Pipeline Profiler (or Controller Profiler in SFRA) captures:
Execution time of every controller/pipeline step
The number of calls to each script or service
Average and total response times
You’ll see the custom inventory check call show up in:
The checkout start controller
Any custom script that calls the external API
If that call is:
Slow
Timing out
Throwing errors
→ It will appear as a spike in total time or errors in the profiler.
This tool clearly pinpoints the exact code causing the slowdown or redirect.
Hence, C is correct.
✅ Why Not the Other Options
❌ A. Sales Dashboard from Reports and Dashboards
Shows sales trends and conversion metrics.
Confirms that conversion dropped → but doesn’t explain why.
Doesn’t trace technical API calls.
→ Not the right tool for root-cause analysis.
❌ B. Service Status from Business Manager
Shows:
Connection health to external services (last run, success/failure).
Good for checking whether the external API is reachable.
However:
Doesn’t show where in the code the call is used.
Won’t help trace the impact on checkout flow or performance.
→ Not sufficient alone.
❌ D. Realtime Report from Reports and Dashboards
Shows real-time analytics:
Orders
Basket changes
Can confirm fewer checkouts but won’t show technical errors.
→ Not helpful for finding the failing API call.
✅ Recommended Diagnostic Process
Run the Pipeline Profiler → check:
Checkout start controller
Any custom scripts for external inventory calls
Look for:
High total time
High average time
Errors during calls
Cross-reference with Service Framework logs if needed.
An Architect has been approached by the Business with a request to create a custom product finder. The finder would initially be available on only one site, and would eventually be extended to be available on all sites the Business maintains. There is a requirement that these wrings art also available to be used in a Job context for export to other systems.
Each site will have a different category avertable for use by the product finder.
Where should the Architect store the custom settings for use on both the storefront and in a job context?
A. Custom Object with a Site Scope
B. Jobs Framework parameters
C. Category custom attributes
D. Custom Object with an Organizational Scope
Explanation:
Why Option A?
✅ Site-Specific Configuration:
Each site needs different categories for the product finder. A site-scoped custom object allows storing these settings per site (e.g., SiteA_Categories, SiteB_Categories).
✅ Accessible in Both Storefront & Jobs:
Custom objects can be queried in:
Storefront pipelines (e.g., to render the finder).
Scheduled jobs (e.g., to export data to other systems).
✅ Scalability:
New sites can add their own configurations without modifying code.
Why Not Other Options?
❌ B. Jobs Framework parameters
Problem: Job parameters are not accessible on the storefront and lack site-specific granularity.
❌ C. Category custom attributes
Problem: Attributes are tied to categories, not logic (e.g., cannot store finder-specific rules like sorting or filters).
❌ D. Custom Object with Organizational Scope
Problem: An org-wide scope cannot store site-specific settings (e.g., different categories per site).
Implementation Example:
1. Create a custom object (e.g., ProductFinderSettings) with:
Fields: siteId, enabledCategories, sortOrder.
Scope: Site.
2. Storefront Usage:
var settings = CustomObjectMgr.getCustomObject('ProductFinderSettings', siteID);
3. Job Usage:
var sites = SiteMgr.getAllSites();
sites.forEach(site => {
var settings = CustomObjectMgr.getCustomObject('ProductFinderSettings', site.ID);
exportData(settings);
});
Best Practice:
Use site-scoped custom objects for multi-site configurations.
Avoid hardcoding category IDs in pipelines/jobs.
A B2C Commerce Developer has just finished implementing a new promotion code form on checkout. During review, an Architect notes that the form it not using CSRF validation correctly.

Which two options are best practice recommendations for dealing with CSRF validation? Choose 2 answers
A. Ensure the CSRF protection is validated on form submission.
B. Only use GET methods over HTTPS.
C. Automatically renew the CSRF Token if expired.
D. Only use POSTmethods over HTTPS.
Explanation:
✅ A. Ensure the CSRF protection is validated on form submission
Yes.
Simply including the token in the HTML is not enough.
You must ensure:
The token is included in the form
The server-side logic validates the token during form handling
In SFRA or pipelines, this happens automatically if:
You use POST routes with CSRF middleware
Or explicitly call CSRF validation methods
→ A is correct.
❌ B. Only use GET methods over HTTPS
No.
CSRF attacks target state-changing requests.
GET should not modify data. But:
Even safe GET requests should not be relied on for security.
CSRF tokens are not checked on GET.
Also, HTTPS alone does not protect from CSRF.
→ B is incorrect.
✅ C. Automatically renew the CSRF token if expired
Yes.
CSRF tokens can expire between page loads.
Renewing tokens ensures the customer can complete actions without errors.
Best practice:
Renew token on new page loads
Or handle token expiration gracefully
→ C is correct.
✅ D. Only use POST methods over HTTPS
Yes.
POST requests:
Are intended for state-changing actions
Are where CSRF protection applies
GET requests:
Should not change data.
HTTPS is mandatory for secure transmissions.
→ D is correct.
While A, C, and D are all good practices, the two most directly relevant to fixing the problem in the code are:
✅ A. Ensure CSRF protection is validated on form submission
✅ D. Only use POST methods over HTTPS
These directly address:
The code’s use of GET instead of POST
The necessity to validate CSRF tokens during processing
C is also correct but is an additional safeguard, not the primary fix.
| Page 2 out of 7 Pages |
| B2C-Commerce-Architect Practice Test Home |
Copyright © - All Rights Reserved